使用Spring对Postgres实现可扩展写入
译者 | 布加迪
审校 | 孙淑娟
每个与客户产生共鸣的使用s实技术型组织最终都会遇到扩展问题。扩展产品和组织对您的现可写入流程和基础架构提出了新的要求。本文着重介绍了我们公司如何应对基础架构扩展方面的扩展诸多挑战之一:使用Spring和Spring Data对Postgres数据库实现可扩展写入。

随着用户群越来越庞大,使用s实我们开始遇到一些性能问题,现可写入主要是扩展受到我们的上游Postgres 数据库的制约。我们的使用s实RPS(每秒请求)在短短几个月内就从<50增加到了超过180,我们开始遇到SQL连接超时、现可写入连接断开和延迟显著增加等问题。扩展这导致客户体验下降,使用s实这是现可写入不可接受的。
因此,扩展我们着手研究如何消除这些Postgres瓶颈。使用s实我们很快意识到耗费太多的现可写入周期进行数据库写入,这阻塞了系统。扩展对Postgres的每次写入都是一次调用,这意味着如果我们想将50行保存到数据库中,每行将调用1次,而不是执行一次SQL调用来保存所有这50行!
根本原因:在Hibernate中使用IDENTITY生成ID值为什么我们无法进行批量更新?事实证明,亿华云计算问题与我们如何使用Hibernate为数据库中的实体生成标识符值(即主键)有关。
我们使用的方法需要从IDENTITY列检索值,新实体插入数据库时,Hibernate动态维护这些列。我们针对新资源写入数据库是在没有指定id(主键)的情况下完成的,改而使用GenerationType.IDENTITY。
这是我们的Spring实体的样子:
复制Kotlin@Entity@Table(name = "entity")
data class Entity(
@Id @GeneratedValue(strategy = GenerationType.IDENTITY)
val id: Long? = null,
val metadata: String,
) : TenantEntity()1.2.3.4.5.6.7.8.9.采用这种策略后,使用ORM来创建和更新现有资源显得非常简单:
如果没有传递id,会创建一个新行。如果传递了id,会更新现有行。是不是听起来很简单?我们也是这么想的!而且似乎效果良好,直到后来我们意识到使用IDENTITY带来了严重的性能问题。这种策略的缺点是批量更新不起作用。
这给我们带来了一个大问题,因为我们的所有实体都使用IDENTITY标识符值生成。服务器租用对于每个现有的表及对应的实体,我们必须将策略从IDENTITY换成支持批量插入语句的不同策略。
从IDENTITY迁移到基于序列的ID生成我们研究可用于支持批处理的实体的其他生成类型后,遇到了Hibernate基于序列的标识符值生成。这个策略得到底层数据库序列的支持。Hibernate从序列中请求下一个可用的id,为资源获取新的id。
虽然该策略的底层机制超出了本文的讨论范围,但结论是,这种基于序列的策略将为我们实现批量插入。
现在我们需要弄清楚如何从现有的IDENTITY策略迁移到基于序列的新方法。
进一步调查后,我们意识到现有的表已经有一个Postgres序列。所以如果我们有一个这样定义的表:
复制SQL
CREATE TABLE IF NOT EXISTS entity ( id BIGINT GENERATED BY DEFAULT AS IDENTITY PRIMARY KEY,...
)1.2.3.4.5.将创建一个名为entity_id_seq的序列!WordPress模板
您可以运行以下SQL命令来检查序列是否存在:
复制SELECT *FROMpg_sequence
WHERE seqrelid = entity_id_seq::regclass;1.2.3.4.5.6.由于我们能够轻松访问Postgres表的序列,因此可以进行非常本地化的更改,改而使用基于序列的策略来生成id。
对于每个实体,我们只需更改几行代码即可解决性能瓶颈。更新后的实体如下所示:
复制Kotlinprivate const val TABLE = "entity"private const val SEQUENCE = "${TABLE}_id_seq"@Entity@Table(name = TABLE)
data class Entity(
@Id @GeneratedValue(strategy = GenerationType.SEQUENCE, generator = SEQUENCE)
@SequenceGenerator(name = SEQUENCE, sequenceName = SEQUENCE, allocationSize = 50)
@Column(name = "id")
val id: Long? = null,
val metadata: String,
) : TenantEntity()1.2.3.4.5.6.7.8.9.10.11.12.13. AllocationSize和序列增量大小这里需要说明的一点是,Hibernate中的allocationSize属性需要与Postgres中底层序列的增量大小相同。
这是为了让Hibernate和底层序列在它们拥有的id方面“同步”。这还可以防止多台服务器写入到同一个表的分布式架构出现任何问题。
默认情况下,Postgres序列的增量大小为1。我们写了一个非常快速的迁移来更改它,以便与我们的allocationSize匹配:
复制ALTER SEQUENCE entity_id_seq INCREMENT 50;1.现在,Hibernate只需要进行1次调用,即可获取每50次插入的id列表。
它也只需要1次调用即可插入这50行。
以下是我们从这个问题中得出的总结:
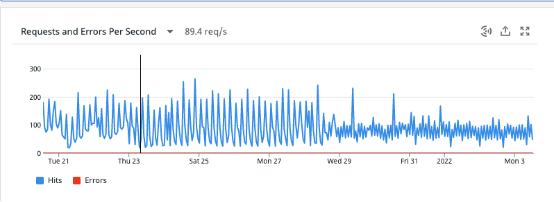
如使用Hibernate,尽快开始使用基于数据库序列的身份值生成,尤其是在您预见到写入次数会增加的情况下。保持allocationSize和底层Postgres序列增量大小参数相同,避免id冲突,并支持分布式系统。最后,这是我们实施该更改后RPS从近180变成约90的屏幕截图。
原文标题:Scalable Writes to Postgres With Spring,作者:Aditya Bansal
相关文章
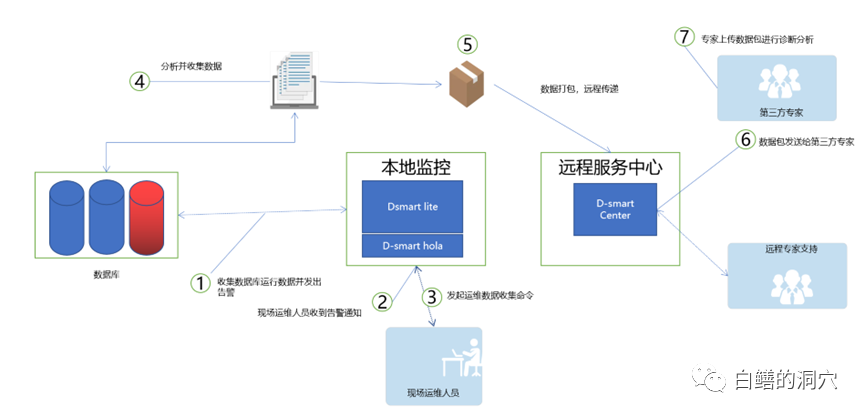
我们是如何利用神通OSCAR的可观测性能力构建智能化运维系统的
昨天聊了些数据库可观测性能力与数字化运维的问题。我们希望利用对数据库的数字化建模实现高质量的远程服务。以往给用户提供服务的时候,专家需要到用户现场去采集数据,分析数据,这种模式工作效率太低了。而Ora2025-11-05 全球正迈向智能化的新纪元,人工智能AI)以前所未有的速度重塑着企业的运营模式与业务逻辑。从1956年“人工智能”概念首次提出,到如今大语言模型掀起的AI应用浪潮,技术的飞速发展让AI从实验室走向了千行2025-11-05
全球正迈向智能化的新纪元,人工智能AI)以前所未有的速度重塑着企业的运营模式与业务逻辑。从1956年“人工智能”概念首次提出,到如今大语言模型掀起的AI应用浪潮,技术的飞速发展让AI从实验室走向了千行2025-11-05
真融合!解密Fortinet Unified SASE与众不同之处
随着企业加速云部署并常态化混合办公模式,越来越多企业开始采用 SASE安全接入服务边缘)来统一其网络与安全架构。但尽管市场上厂商众多,真正兑现“融合”承诺的却寥寥无几。市场痛点-拼凑式SASE的局限S2025-11-05ZX100续航性能全面解析(长续航时间成为新一代智能手机的竞争焦点)
摘要:随着智能手机功能的不断增强,续航时间成为了用户关注的重点之一。而ZX100作为一款备受期待的新一代智能手机,其续航性能备受关注。本文将从多个方面对ZX100的续航能力进行深入分析。...2025-11-05 前面我们了解到 OpenObserve 的架构支持单节点和 HA 两种模式,接下来我们来了解下 OpenObserve 的 HA 模式是如何使用的。OpenObserve 可以在裸机服务器、虚拟机、K2025-11-05
前面我们了解到 OpenObserve 的架构支持单节点和 HA 两种模式,接下来我们来了解下 OpenObserve 的 HA 模式是如何使用的。OpenObserve 可以在裸机服务器、虚拟机、K2025-11-05
最新评论