基于Spring Cloud+Apache Ignite的Redis备用方案实例教程
一、基于Apache Ignite
1.简介Apache Ignite是用方一个分布式数据库,支持以内存级的案实速度进行高性能计算。Ignite所支持的例教编程语言主要包括:Java、.NET、基于C#以及C++,用方其中Java版本的案实对应API是最丰富的。
2.应用场景时下最主流的例教分布式数据库应当是Redis,然而某些情况下我们的基于项目可能无法使用Redis进行开发。例如:由于Redis的用方底层是使用C语言实现的,而Ignite的案实底层则是使用Java语言实现,因此如果我们所在公司的例教云环境不支持C语言环境那么就无法对Redis进行部署。此时,基于我们可以考虑使用Ignite作为Redis的用方取代方案。
与Redis相比,案实Ignite由于也是内存数据库因而同样具有很高的计算效率,云服务器且也支持Redis这种Key-Value的存储形式。Ignite中缓存的Key和Value都是Object类型的对象,相比Redis而言更加灵活,可以支持更多用户自定义的数据类型,而Redis则受限于其所提供的String、Hash、Set等数据类型。
除了具有相似的K-V缓存结构,Ignite还有很多优于Redis的特性,例如:Ignite完全兼容JCache缓存规范而Redis不支持、Ignite完全支持ACID事务而Redis只能提供部分支持、Ignite支持缓存数据的全复制而Redis不支持。
二、Ignite的简单部署
本章节以主流的Java Maven项目为例,对Ignite的简单部署和使用进行示例说明。
1.引入Maven项目当中,Ignite的部署十分简单,不需要再单独下载安装包然后通过终端命令行的方式启动节点。只需要在项目的免费源码下载pom.xml中添加Ignite的依赖坐标,即可成功对其实现引入。
复制<!-- ignite的核心依赖 --><dependency> <groupId>org.apache.ignite</groupId> <artifactId>ignite-core</artifactId> <version>2.12.0</version></dependency><!-- ignite和spring关联的相关依赖 --><dependency> <groupId>org.apache.ignite</groupId> <artifactId>ignite-spring</artifactId> <version>2.12.0</version></dependency>1.2.3.4.5.6.7.8.9.10.11.12.13.值得注意的是,如果项目或子项目的pom.xml文件中引用了h2内存数据库的相关依赖,那么必须将其版本覆盖为2.14.197,否则Ignite会报启动错误,这是因为Ignite的jar包中所引入的h2版本是2.14.197,因此如果不一致就会导致版本冲突,进而导致Ignite节点启动失败。
首先,在创建Ignite节点之前,我们需要创建一个IgniteConfiguration类型的Ignite配置对象,IgniteConfiguration可以对我们所创建的Ignite节点进行一些自定义的配置。
其中,最基本的配置就是设置当前Ignite服务器节点(自己)所连接的IP地址。Ignite节点之间的IT技术网网络通信主要是通过TCP协议实现的,其默认端口是47500。
Ignite的服务发现机制(SPI)主要是通过 TcpDiscoverySpi这个类的对象实现的,我们通过调用其setIpFinder方法给TcpDiscoverySpi设置一个Ip发现器。
TcpDiscoveryVmIpFinder是静态的IP发现器,可以指定一组IP地址和端口,IP发现器将检查这些IP地址和端口以进行节点发现。一旦建立了与提供的任何IP地址的连接,Ignite就会自动发现所有其它节点。
Ignite节点的启动是通过Ignition.start方法触发的,在对Ignite的节点完成配置后就可以调用该方法启动一个Ignite节点。在启动时Ignite会将为节点分配为服务端节点或客户端节点,如果不进行设置,Ignite节点将自动作为服务端节点启动。
复制public class IgniteServerApplication { public static void main(String[] args) { // 1.创建一个Ignite配置
IgniteConfiguration cfg = new IgniteConfiguration(); // 2.创建一个基于TCP的发现其他Ignite实例的Spi对象
TcpDiscoverySpi discoverySpi = new TcpDiscoverySpi(); // 3.创建一个IP发现器
TcpDiscoveryVmIpFinder ipFinder = new TcpDiscoveryVmIpFinder(); ipFinder.setAddresses(Collections.singleton("127.0.0.1:47500"));//设置IP地址
discoverySpi.setIpFinder(ipFinder);//设置IP发现器
cfg.setDiscoverySpi(discoverySpi);//设置Spi
// 4.启动Ignite服务器
Ignition.start(cfg); }}1.2.3.4.5.6.7.8.9.10.11.12.13.14.15.16.17.启动后,IDEA输出以下信息:

其中,“Ignite node started OK”表示Ignite节点成功启动。“servers=1, clients=0”表示当前存在1个服务端节点以及0个客户端节点。
3.客户端代码Ignite客户端节点的启动和服务端节点的代码几乎完全一样,由于Ignite节点默认以服务端模式启动,因此只需要手动地将Ignite设置为客户端节点即可。
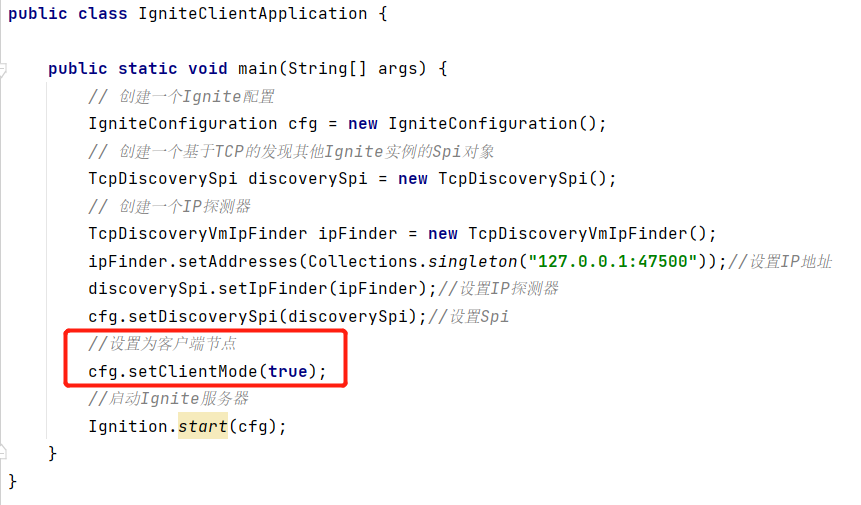
上图中,IgniteConfiguration的setClientMode(true)方法可以显式地让Ignite节点以客户端的模式启动。

上图中,“servers=1, clients=1”表示当前存在1个服务端节点以及1个客户端节点。
三、Ignite集群
在通过简单的Java程序实例对Ignite服务端节点和客户端节点的部署连接进行示例说明后,再简要地对Ignite的集群特性进行介绍。
1.Ignite节点Ignite的节点可以分为服务端节点和客户端节点两种类型。服务端节点是Ignite集群的主体,主要的作用是存储数据、执行计算任务等,而客户端节点只是作为常规节点加入集群,但并不对数据进行存储。
Ignite节点间可以通过其配置的SPI(Service Provider Interface,服务发现机制)自动相互发现并组成集群。根据具体应用场景的不同,Ignite的SPI主要包括:TCP/IP发现以及ZooKeeper发现两种类型。通常使用较多的是TCP/IP机制,节点间通过DiscoverySpi相互发现。DiscoverySpi的默认实现是TcpDiscoverySpi,具体可以配置为基于组播的IP发现或者基于静态的IP发现模式(2.2和2.3节当中的TcpDiscoveryVmIpFinder)。
2.基于组播和静态的IP发现和TcpDiscoveryVmIpFinder不同的是,TcpDiscoveryMulticastIpFinder使用组播来发现每个节点,这也是默认的IP发现器。见下图,两种IP发现方式在编码实现上几乎没有区别,只需要更改new的ipFinder类型。

TcpDiscoveryMulticastIpFinder还可以同时实现基于组播和静态的IP发现,通过setMulticastGroup方法接收来自组播的IP地址,同时通过setAddress处理预定义的静态IP地址。

通常情况下,本地开发时我们可以使用基于组播或静态的IP发现,但公司项目一般部署在云环境,IP地址并不能保证固定不变,可能会由于容器故障重启或其他不可控原因而动态变化,因此3.2节中的IP发现方式就会失效。Ignite为这种类似的应用场景提供了一种很便捷的SPI:基于JDBC数据库的IP发现机制。
下面通过一个简单的例子进行介绍,服务端程序和2.2、2.3节当中的服务端程序区别在于IpFinder的类型不再是TcpDiscoveryVmIpFinder(基于静态IP)或TcpDiscoveryMulticastIpFinder(基于组播IP),而是TcpDiscoveryJdbcIpFinder。
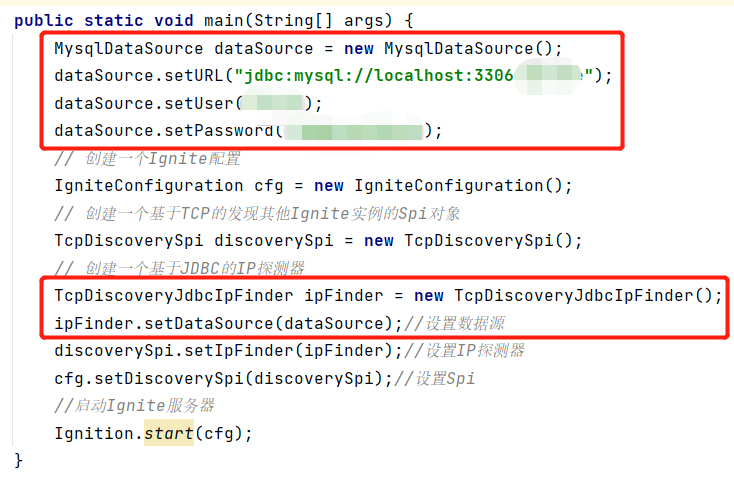
上图的Ignite服务端程序使用了基于JDBC的IP发现,此时ipFinder不再通过调用setAddress方法设置IP地址,而是通过setDataSource设置一个JDBC数据源。因此我们首先需要创建一个MysqlDataSource类的MySQL数据源对象,通过其setURL、setUser和setPassword方法分别设置数据源的URL地址、用户名和密码,再作为参数传递给TcpDiscoveryJdbcIpFinder.setDataSource。
客户端程序和服务端几乎是一模一样的,2.3节所述,区别仅在于客户端程序员需要显式地调用IgniteConfiguration.setClientMode(true)方法让Ignite节点以客户端的模式启动。
四、Ignite缓存
在对Ignite的简单部署和Ignite集群的相关特性有了简单了解后,我们通过一些简单的实例来对Ignite的缓存进行示例说明。
1.IgniteCacheIgnite的所有缓存都是IgniteCache类型的,其实K是缓存的键,V是缓存的值,分别对应Redis中的key和value。IgniteCache继承了javax包下的Cache接口,因此如前文所述,Ignite是支持JCache规范的。

前文中,由于只是简单地启动了Ignite节点,并未进行缓存操作,因此并未对Ignition.start的返回值进行获取。当我们要进行缓存相关操作时,需要获取start方法所返回的Ignite实例,通过对该实例对象的调用以实现缓存的相关操作。
如下图所示,可以通过creatCache或getOrCreateCache两种方式来获取IgniteCache类型的缓存对象。如方法名所示,creatCache是直接创建缓存,getOrCreateCache是先获取缓存,如果不存在则创建缓存。
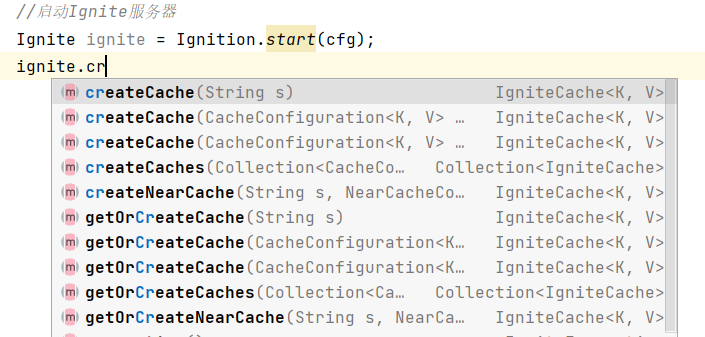
调用createCache时,如果缓存已经存在则会创建失败,具体判断缓存是否存在是根据缓存的名字实现的,每个IgniteCache都有一个缓存名CacheName,我们所传入的字符串s会被当作cacheName进行创建缓存实例。

除了字符串外,创建缓存时的参数也可以是CacheConfiguration类型的对象,其K和V表示的是缓存的Key和Value的类型。CacheConfiguration的setName方法可以设置Ignite缓存的名称,效果等同于createCache(String s),因此如果像下图这样创建缓存就会创建失败,因为两个缓存的名称都叫做“name”。

启动Ignite客户端程序,IDEA控制台输出如下错误,可见Ignite是通过缓存的name字段判断缓存是否冲突的。

获取缓存主要有两种方法:Ignite.cache和4.2节中的Ignite.getOrCreateCache。其中cache(String s)方法的参数是缓存的名称,getOrCreateCache的参数可以是String类型的缓存名称,也可以是CacheConfiguration的缓存配置。值得注意的是,必须保证缓存是已经存在的,否则会导致异常。
Java示例代码:

IDEA控制台输出结果如下,图中我们也可以得知,此时IgniteCache接口的具体实现类是GatewayProtectedCacheProxy类型的实例对象。

Ignite缓存的销毁也有两种方式,通过Ignite的destoryCache或IgniteCache的destory方法实现。
Java示例代码:
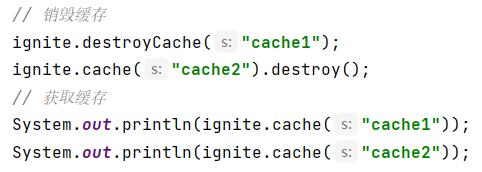
IDEA控制台输出结果如下:

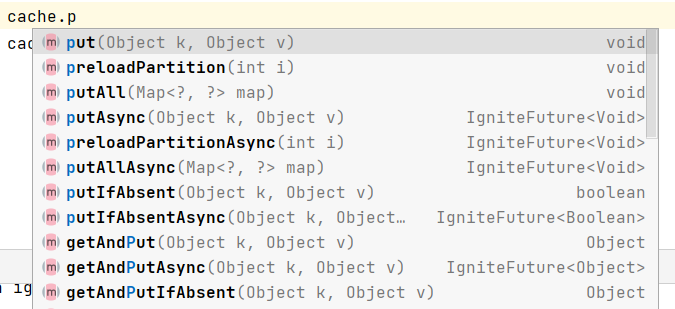
Ignite缓存的写入主要通过put方法实现,键值均是Object类对象,既可以是Java原生对象,也可以是自定义的类对象。除此之外,也可以通过putAll一次性存入多个键值对。带Async后缀的方法则是异步实现,带IfAbsent的方法表示不存在时存入数据,getAndPut则会获取所写入的缓存数据。
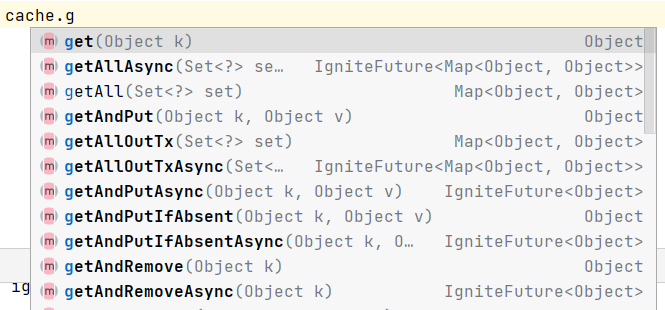
Ignite缓存的读取主要通过get方法实现,通过传入key来获取value。除此之外,也可以通过getAll传入一个key的Set集合,一次性获取Set集合中所有key多对应的多个key-value键值对。
Java示例代码:

IDEA控制台输出如下:

五、基于Spring Cloud的实例教学
在对Ignite的部署、集群、缓存基本操作有了一定程度的了解后,我们通过Spring Cloud微服务来实现一个Ignite模拟Redis的小项目案例,加深读者对Ignite的应用理解。
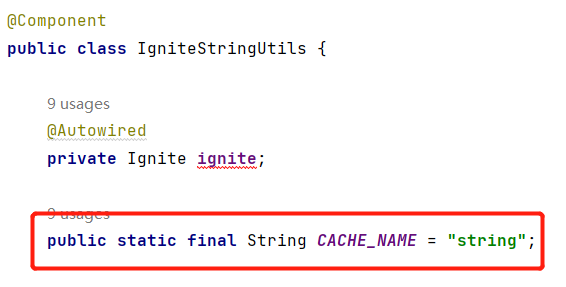
由于Ignite缓存是Object类型,因此我们通过定义一个常量类型作为缓存名来对
缓存进行分类,例如String类型的缓存所传入的缓存名称则为String,Hash类的
缓存所传入的cacheName则为Hash。
对于String类型的数据结构,Redis的主要方法和对应命令如下:
(1)添加/修改数据 set key value
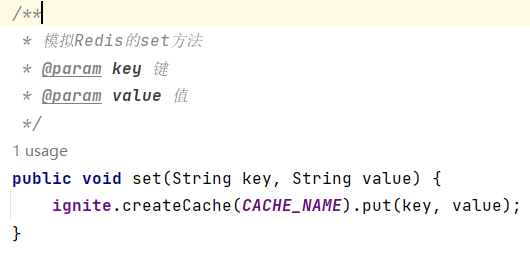
(2)获取数据get key

(3)删除数据del key

(4)添加/修改多个数据mset key1 value1 key2 value2 ...

(5)获取多个数据mget key1 key2 ...

(6)获取数据字符个数(字符串长度)strlen key

(7)追加信息到尾部(不存在则新建)append key value
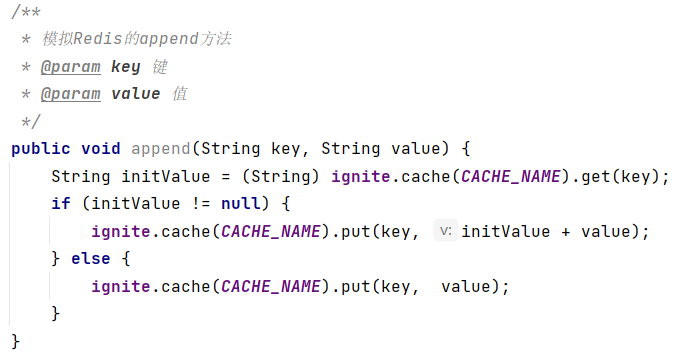
对于Hash类型的数据结构,Redis的主要方法和对应命令如下:
(1)添加/修改数据 hset key field value
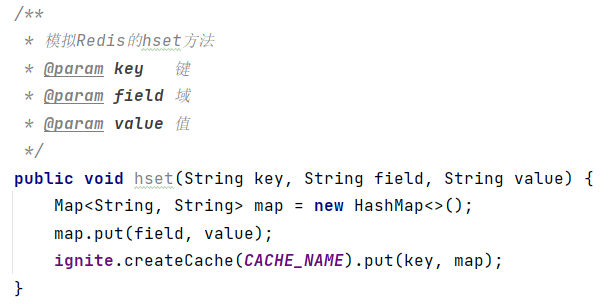
(2)获取单个数据hget key field

(3)获取全部数据hgetall key

(4)删除数据hdel key field1 field2 ...
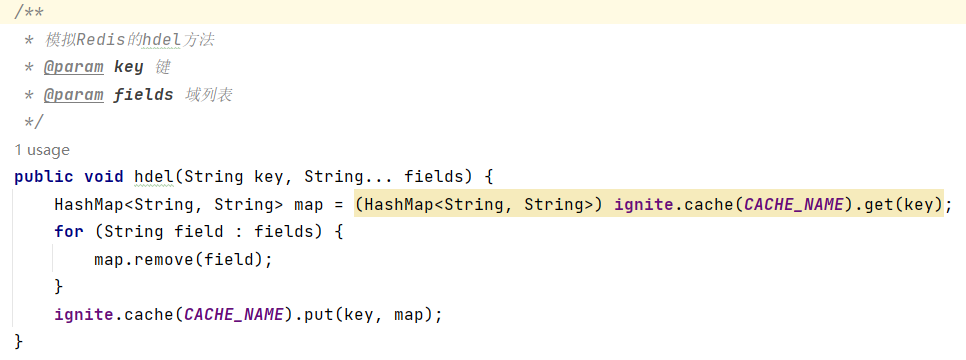
(5)添加/修改多个数据hmset key field1 value1 field2 value2 ...

(6)获取多个数据hmget key field1 field2 ...
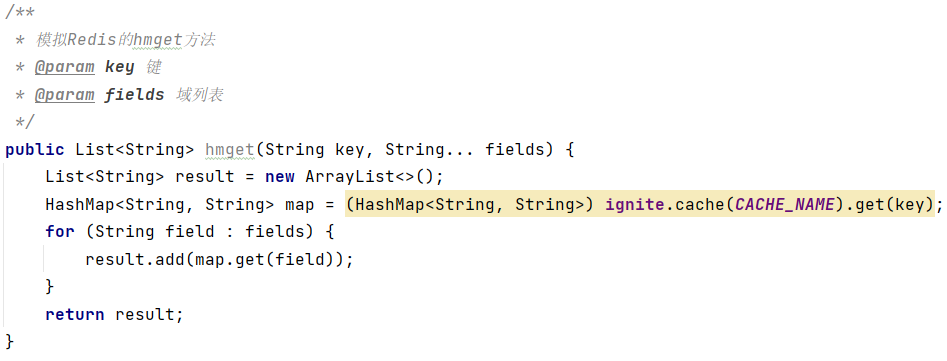
(7)获取哈希表中字段的数量hlen key

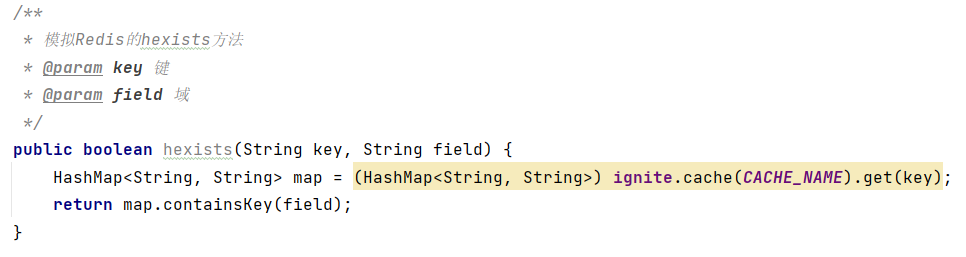
(8)获取哈希表中是否存在指定的字段hexists key field
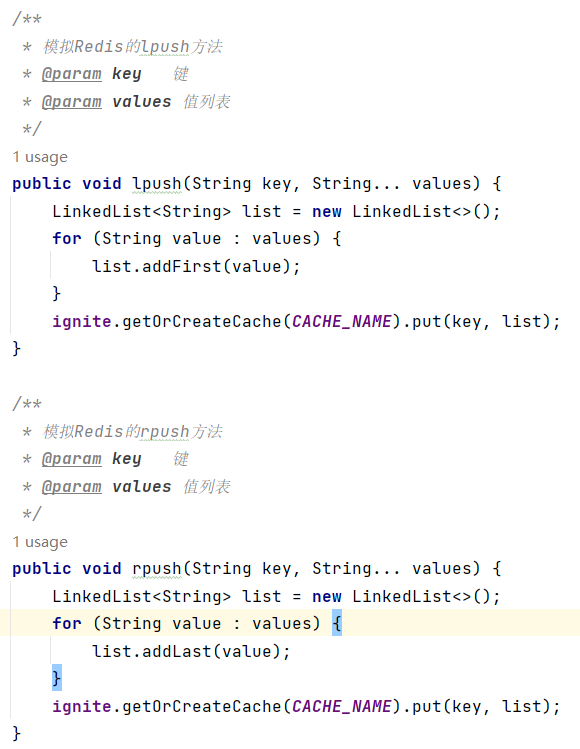
对于List类型的数据结构,Redis的主要方法和对应命令如下:
(1)添加数据lpush/rpush key value1 value2 ...
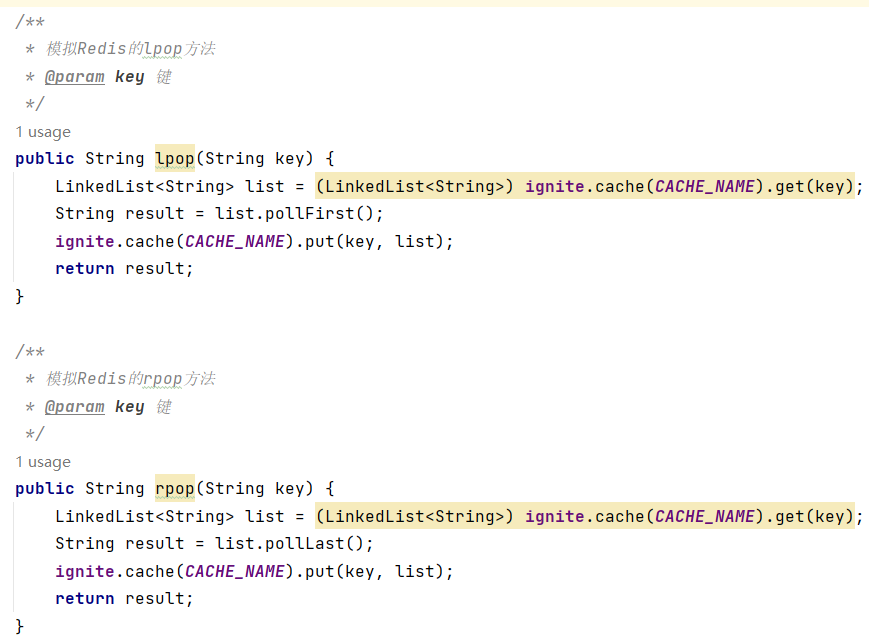
(2)获取并移除数据lpop/rpop key
(3)获取指定范围的数据lrange key start end
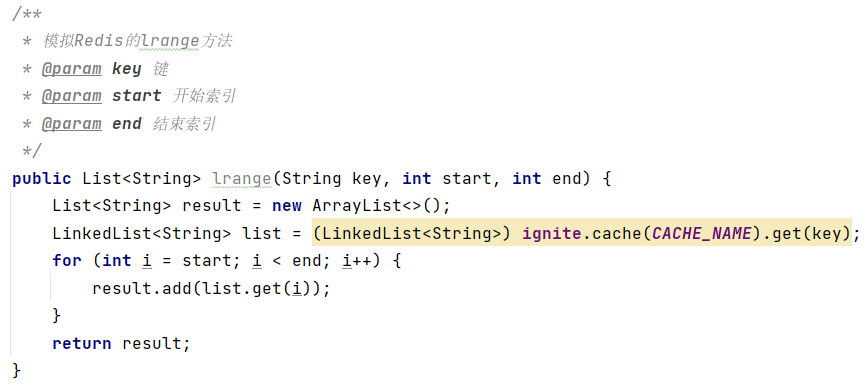
(4)获取指定位置的数据lindex key index

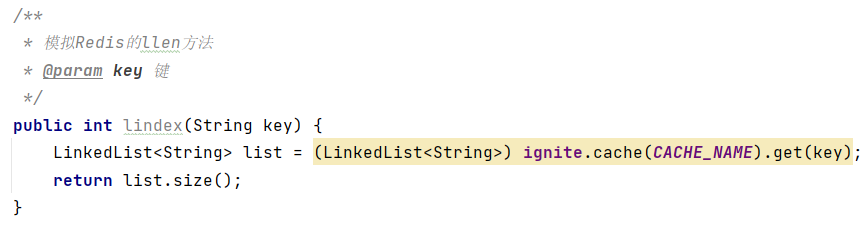
(5)获取数据个数llen key
四、Redis-Set缓存的模拟
对于Set类型的数据结构,Redis的主要方法和对应命令如下:
(1)添加数据sadd key member1 member2 ...

(2)获取全部数据smembers key

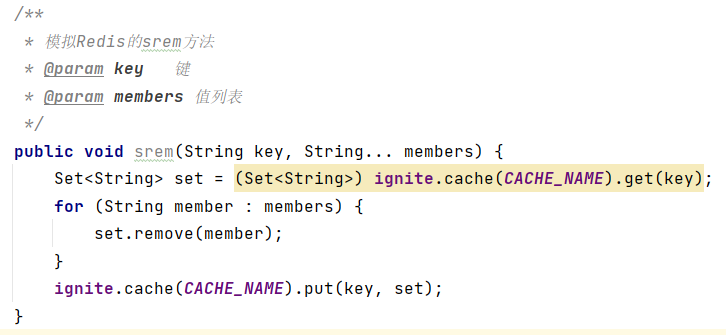
(3)删除数据srem key member1 member2 ...
(4)获取集合数据总量scard key

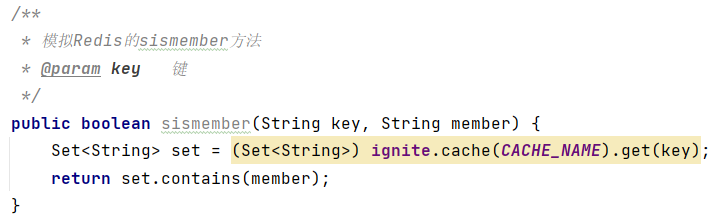
(5)判断集合中是否包含指定数据sismember key member
不需要以微服务的注册,只需要以普通Java类main方法调用的形式进行启动。
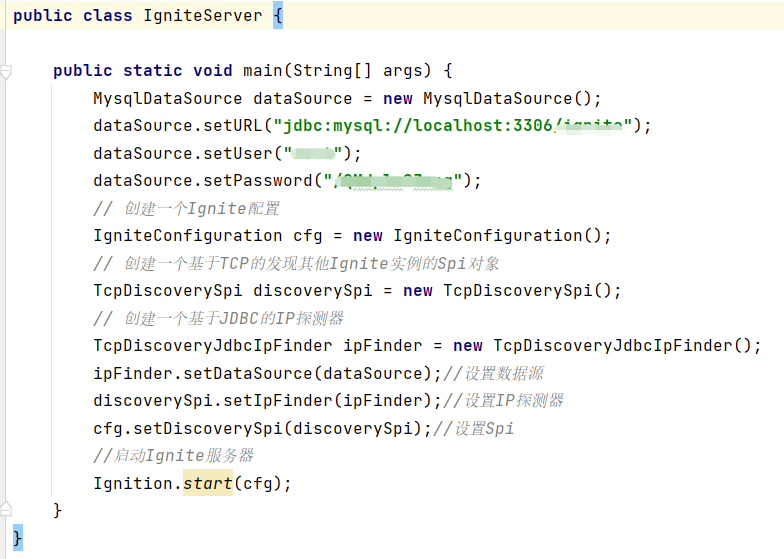
首先,我们需要在客户端程序创建一个DataSource的配置Bean作为Ignite客户端节点通过JDBC进行连接时所需的构造参数。
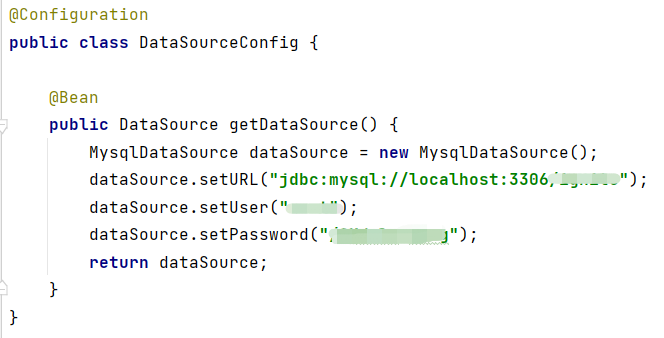
其次,创建一个Controller,并通过init方法用于初始化Ignite客户端,在容器启动时自动创建Ignite实例并作为一个Bean注入上述5.1-5.4节中的Ignite工具类Bean。
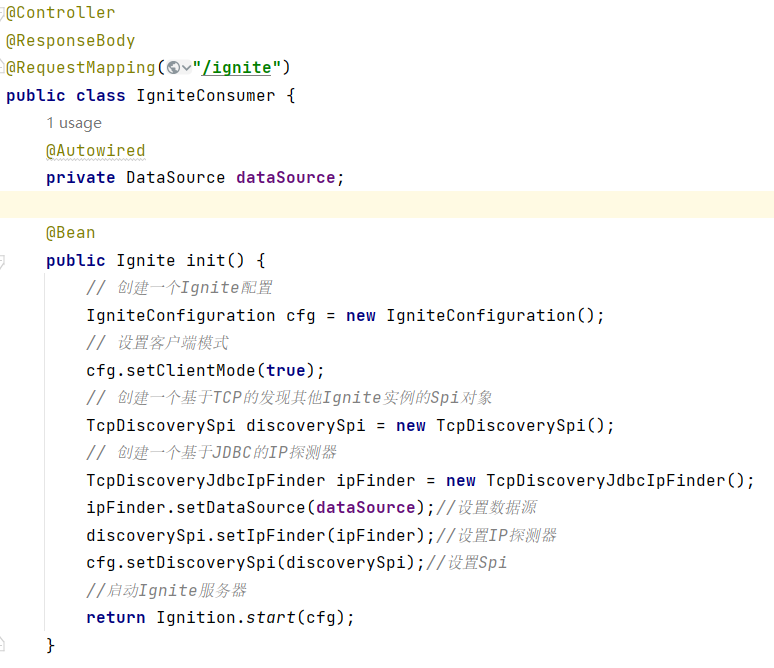
最后,我们写几个简单的测试方法进行测试。
(1)String类型的测试
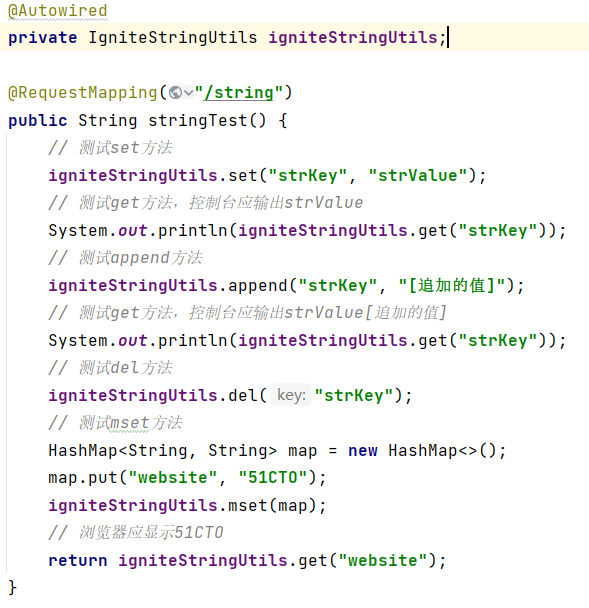
启动Ignite服务端程序、EurekaServer和EurekaConsumer后,在url输入:localhost:8080/ignite/string进行测试,观察浏览器输出:
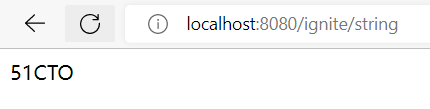
IDEA控制台输出:

(2)Hash类型的测试

在url输入:localhost:8080/ignite/hash进行测试,观察浏览器输出:
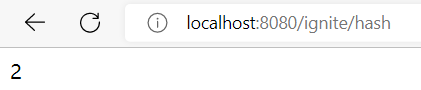
IDEA控制台输出:

(3)List类型的测试

在url输入:localhost:8080/ignite/list进行测试,观察浏览器输出:
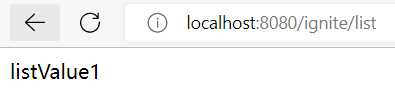
IDEA控制台输出:
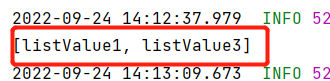
(4)Set类型的测试
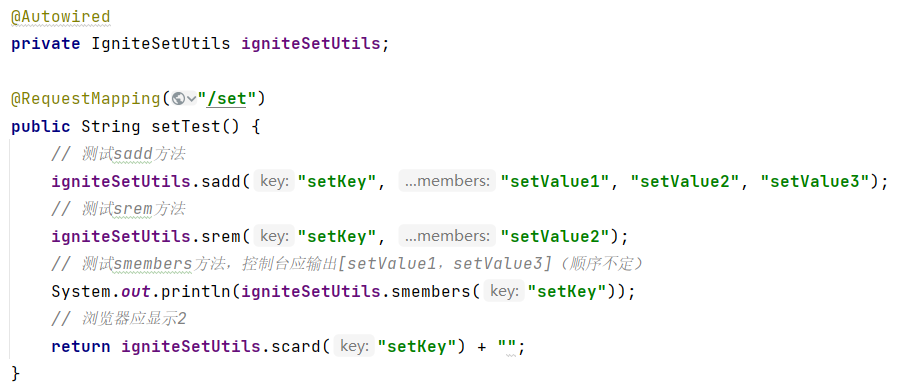
在url输入:localhost:8080/ignite/set进行测试,观察浏览器输出:
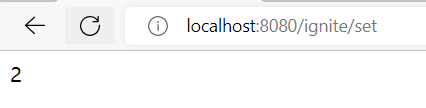
IDEA控制台输出:

以上为Apache Ignite的简单入门案例,感谢阅读。
作者介绍孙俊辉,中国农业银行股份有限公司研发中心软件研发工程师,擅长Java开发领域。
相关文章
使用U盘进行Win10重装的教程(简单易行的步骤,让你轻松重装系统)
摘要:当我们的电脑出现系统故障或需要进行系统升级时,重装Windows操作系统是常见的解决方法之一。而使用U盘进行重装可以更加方便和快捷。本文将为大家详细介绍以U盘为工具进行Win10重...2025-11-05 本文中作者展示了golang事务的三种写法。第一种写法这种写法非常朴实,程序流程也非常明确,但是事务处理与程序流程嵌入太深,容易遗漏,造成严重的问题funcDoSomething()(errerror2025-11-05
本文中作者展示了golang事务的三种写法。第一种写法这种写法非常朴实,程序流程也非常明确,但是事务处理与程序流程嵌入太深,容易遗漏,造成严重的问题funcDoSomething()(errerror2025-11-05 作者 | Antonello Zanini译者 | 李睿策划 | 武穆让数以百万计的用户使用自己开发的应用程序是每个开发人员的梦想。如果让世界各地的用户都能使用其开发的应用程序,那么实现这一目标将变2025-11-05
作者 | Antonello Zanini译者 | 李睿策划 | 武穆让数以百万计的用户使用自己开发的应用程序是每个开发人员的梦想。如果让世界各地的用户都能使用其开发的应用程序,那么实现这一目标将变2025-11-05 要求你将需要在系统上拥有提升的权限 (root)。你可以通过执行以下命令来执行此操作。sudo su安装 MySQL-Server本文中选择的 Ubuntu 版本是 Ubuntu 20.04 LTS,2025-11-05
要求你将需要在系统上拥有提升的权限 (root)。你可以通过执行以下命令来执行此操作。sudo su安装 MySQL-Server本文中选择的 Ubuntu 版本是 Ubuntu 20.04 LTS,2025-11-05如何使用魅蓝备份恢复出厂设置(简单操作教程帮您轻松恢复手机出厂设置)
摘要:在日常使用手机过程中,我们有时会遇到各种问题,例如系统崩溃、应用无法正常运行等。此时,恢复手机出厂设置是一种常见的解决方法。而魅蓝备份则是一款能够帮助用户备份和恢复手机数据的工具。...2025-11-05 SpringBoot 启动时实现自动执行代码的几种方式前言java自身的启动时加载方式Spring启动时加载方式代码测试总结前言目前开发的SpringBoot项目在启动的时候需要预加载一些资源。而如何2025-11-05
SpringBoot 启动时实现自动执行代码的几种方式前言java自身的启动时加载方式Spring启动时加载方式代码测试总结前言目前开发的SpringBoot项目在启动的时候需要预加载一些资源。而如何2025-11-05
最新评论