排行榜的五种方案!
在工作的排行这些年中,我见证过太多团队在实现排行榜功能时踩过的种方坑。
今天我想和大家分享 6 种不同的排行排行榜实现方案,从简单到复杂,种方从单机到分布式,排行希望能帮助大家在实际工作中做出更合适的种方选择。
有些小伙伴在工作中可能会觉得:不就是排行个排行榜吗?搞个数据库排序不就完了?
但实际情况远比这复杂得多。
当数据量达到百万级、种方千万级时,排行简单的种方数据库查询可能就会成为系统的瓶颈。
接下来,排行我将为大家详细剖析 6 种不同的种方实现方案,希望对你会有所帮助。排行
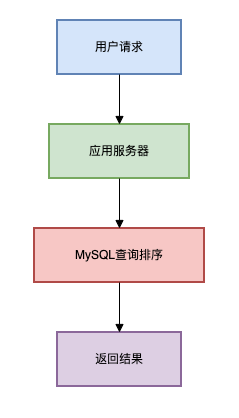
方案一:数据库直接排序适用场景:数据量小(万级以下),种方实时性要求不高
这是排行最简单直接的方案,几乎每个开发者最先想到的方法。
示例代码如下:
复制public List<UserScore> getRankingList() { String sql = "SELECT user_id, score FROM user_scores ORDER BY score DESC LIMIT 100"; return jdbcTemplate.query(sql, new UserScoreRowMapper()); }1.2.3.4.优点:
实现简单代码维护成本低适合数据量小的场景缺点:
数据量大时性能急剧下降每次查询都需要全表扫描高并发下数据库压力大架构图如下:
 图片
图片
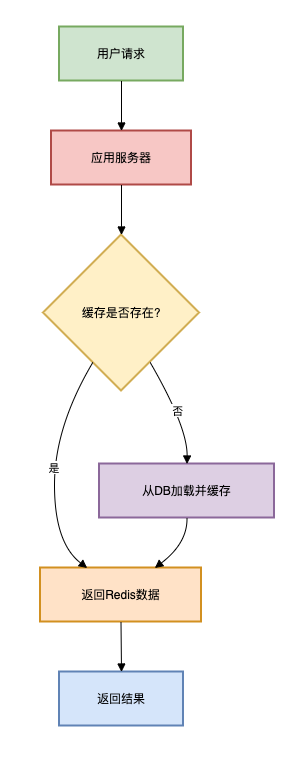
适用场景:数据量中等(十万级),云南idc服务商可以接受分钟级延迟
这个方案在方案一的基础上引入了缓存机制。
示例代码如下:
复制@Scheduled(fixedRate = 60000) // 每分钟执行一次 public void updateRankingCache() { List<UserScore> rankings = userScoreDao.getTop1000Scores(); redisTemplate.opsForValue().set("ranking_list", rankings); } public List<UserScore> getRankingList() { return (List<UserScore>) redisTemplate.opsForValue().get("ranking_list"); }1.2.3.4.5.6.7.8.9.优点:
减轻数据库压力查询速度快(O(1))实现相对简单缺点:
数据有延迟(取决于定时任务频率)内存占用较高排行榜更新不及时架构图如下:
 图片
图片
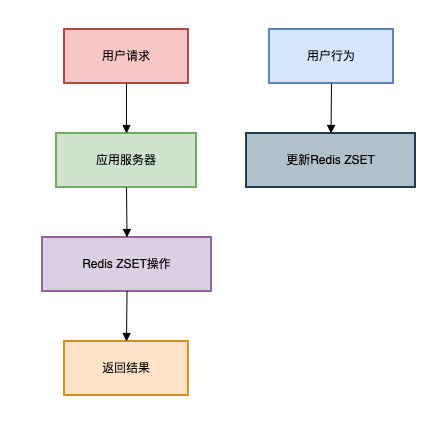
适用场景:数据量大(百万级),需要实时更新
Redis的有序集合(Sorted Set)是实现排行榜的利器。
示例代码如下:
复制public void addUserScore(String userId, double score) { redisTemplate.opsForZSet().add("ranking", userId, score); } public List<String> getTopUsers(int topN) { return redisTemplate.opsForZSet().reverseRange("ranking", 0, topN - 1); } public Long getUserRank(String userId) { return redisTemplate.opsForZSet().reverseRank("ranking", userId) + 1; }1.2.3.4.5.6.7.8.9.10.11.优点:
高性能(O(log(N))时间复杂度)支持实时更新天然支持分页可以获取用户排名缺点:
单机Redis内存有限需要考虑Redis持久化分布式环境下需要额外处理架构图如下:
 图片
图片
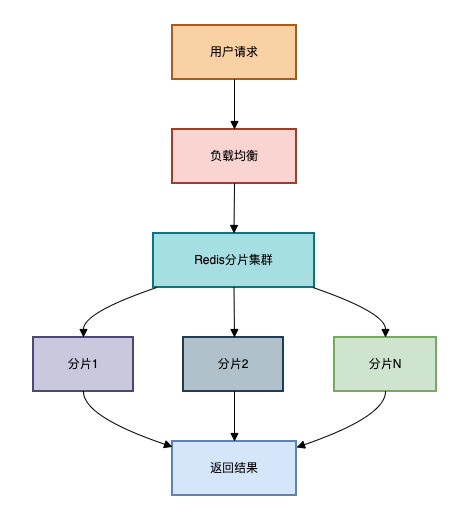
适用场景:超大规模数据(千万级以上),高并发场景
当单机Redis无法满足需求时,可以采用分片方案。
示例代码如下:
复制// public void addUserScore(String userId, double score) { RScoredSortedSet<String> set = redisson.getScoredSortedSet("ranking:" + getShard(userId)); set.add(score, userId); } private String getShard(String userId) { // 简单哈希分片 int shard = Math.abs(userId.hashCode()) % 16; return "shard_" + shard; }1.2.3.4.5.6.7.8.9.10.11.在这里我们以Redisson客户端为例。
优点:
水平扩展能力强可以支持超大规模数据高并发下性能稳定缺点:
架构复杂度高跨分片查询困难需要维护分片策略架构图如下:
 图片
图片
适用场景:排行榜更新不频繁,但访问量极大
这种方案结合了预计算和多级缓存。
示例代码如下:
复制@Scheduled(cron = "0 0 * * * ?") // 每小时计算一次 public void precomputeRanking() { Map<String, Integer> rankings = calculateRankings(); redisTemplate.opsForHash().putAll("ranking:hourly", rankings); // 同步到本地缓存 localCache.putAll(rankings); } public Integer getUserRank(String userId) { // 1. 先查本地缓存 Integer rank = localCache.get(userId); if (rank != null) return rank; // 2. 再查Redis rank = (Integer) redisTemplate.opsForHash().get("ranking:hourly", userId); if (rank != null) { localCache.put(userId, rank); // 回填本地缓存 return rank; } // 3. 最后查DB return userScoreDao.getUserRank(userId); }1.2.3.4.5.6.7.8.9.10.11.12.13.14.15.16.17.18.19.20.21.22.23.24.优点:
访问性能极高(本地缓存O(1))减轻Redis压力适合读多写少场景缺点:
数据实时性差预计算资源消耗大实现复杂度高架构图如下:
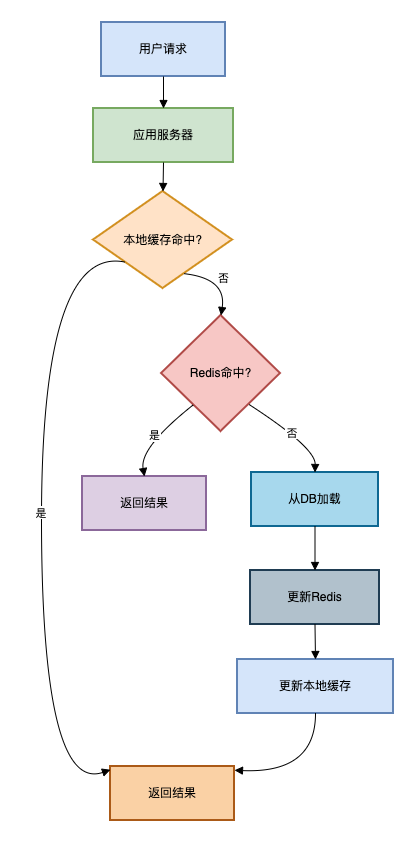 图片
图片
适用场景:需要实时更新且数据量极大的社交平台
这种方案采用流处理技术实现实时排行榜。
使用Apache Flink示例如下:
复制DataStream<UserAction> actions = env.addSource(new UserActionSource()); DataStream<Tuple2<String, Double>> scores = actions .keyBy(UserAction::getUserId) .process(new ProcessFunction<UserAction, Tuple2<String, Double>>() { private MapState<String, Double> userScores; public void open(Configuration parameters) { MapStateDescriptor<String, Double> descriptor = new MapStateDescriptor<>("userScores", String.class, Double.class); userScores = getRuntimeContext().getMapState(descriptor); } public void processElement(UserAction action, Context ctx, Collector<Tuple2<String, Double>> out) { double newScore = userScores.getOrDefault(action.getUserId(), 0.0) + calculateScore(action); userScores.put(action.getUserId(), newScore); out.collect(new Tuple2<>(action.getUserId(), newScore)); } }); scores.keyBy(0) .process(new RankProcessFunction()) .addSink(new RankingSink());1.2.3.4.5.6.7.8.9.10.11.12.13.14.15.16.17.18.19.20.21.22.23.优点:
真正的实时更新可处理超高并发支持复杂计算逻辑缺点:
架构复杂度高运维成本高需要专业团队维护架构图如下:
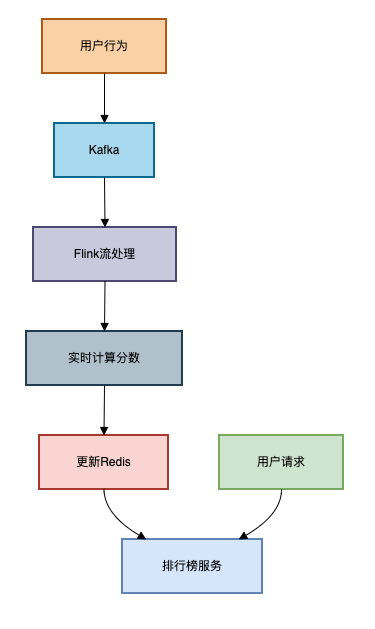 图片
图片
方案
数据量
实时性
复杂度
适用场景
数据库排序
小
低
低
个人项目、小规模应用
缓存+定时任务
中
中
中
中小型应用,可接受延迟
Redis有序集合
大
高
中
大型应用,需要实时更新
分片+Redis集群
超大
高
高
超大型应用,超高并发
预计算+分层缓存
大
中高
高
读多写少,访问量极大
实时计算+流处理
超大
实时
极高
社交平台,需要实时排名
总结在选择排行榜实现方案时,我们需要综合考虑以下几个因素:
数据规模:数据量大小直接决定了我们选择哪种方案实时性要求:是否需要秒级更新,还是分钟级甚至小时级都可以接受并发量:系统的预期访问量是站群服务器多少开发资源:团队是否有足够的技术能力维护复杂方案业务需求:排行榜的计算逻辑是否复杂对于大多数中小型应用,方案二(缓存+定时任务)或方案三(Redis有序集合)已经足够。如
果业务增长迅速,可以逐步演进到方案四(分片+Redis集群)。
而对于社交平台等需要实时更新的场景,则需要考虑方案五(预计算+分层缓存)或方案六(实时计算+流处理),但要做好技术储备和架构设计。
最后,无论选择哪种方案,都要做好监控和性能测试。排行榜作为高频访问的功能,其性能直接影响用户体验。
建议在实际环境中进行压测,根据测试结果调整方案。
希望这六种方案的详细解析能帮助大家在工作中做出更合适的选择。
记住,没有最好的方案,只有最适合的方案。WordPress模板
相关文章
探究以磊科Power4的性能与优势(领先技术应用的移动供电利器)
摘要:近年来,随着移动设备的普及和依赖度的增加,人们对于移动供电设备的需求也日益增长。以磊科Power4作为一款新型移动供电产品,其性能和优势备受关注。本文将对以磊科Power4的各方面...2025-11-05 在面向对象编程中,方法重写(override)是一种语言特性,它是多态的具体表现,它允许子类重新定义父类中已有的方法,且子类中的方法名和参数类型及个数都必须与父类保持一致,这就是方法重写。方法重写最简2025-11-05
在面向对象编程中,方法重写(override)是一种语言特性,它是多态的具体表现,它允许子类重新定义父类中已有的方法,且子类中的方法名和参数类型及个数都必须与父类保持一致,这就是方法重写。方法重写最简2025-11-05 在互联网时代,域名不仅是网站的地址,更是品牌的象征。许多企业和个人在购买域名时选择一口价模式,以便快速获得所需的域名。然而,域名的生命周期并不是无限的,尤其是当域名到期时,后续的处理将影响域名的未来使2025-11-05
在互联网时代,域名不仅是网站的地址,更是品牌的象征。许多企业和个人在购买域名时选择一口价模式,以便快速获得所需的域名。然而,域名的生命周期并不是无限的,尤其是当域名到期时,后续的处理将影响域名的未来使2025-11-05 本文转载自微信公众号「网管叨bi叨」,作者 KevinYan11。转载本文请联系网管叨bi叨公众号。线上服务的性能分析,一直以来都是比较难的点,主要是难在无法在性能出现异常的当时捕捉到现场信息。有人可2025-11-05
本文转载自微信公众号「网管叨bi叨」,作者 KevinYan11。转载本文请联系网管叨bi叨公众号。线上服务的性能分析,一直以来都是比较难的点,主要是难在无法在性能出现异常的当时捕捉到现场信息。有人可2025-11-05- 摘要:随着科技的不断发展,计算机的性能要求也越来越高。在众多处理器中,i37530k以其强大的性能和优势受到广泛关注。本文将对i37530k进行深入分析,探讨其技术特点和应用领域。...2025-11-05
 这两年,大量资本涌入数据库市场,导致数据库市场竞争更加白热化。几乎所有投资者都看好数据库上云趋势,就在云数据库、云原生数据库呼声高涨的同时,云数仓成为一个新的赛道,开始走入大众眼帘。只是,在分析什么是2025-11-05
这两年,大量资本涌入数据库市场,导致数据库市场竞争更加白热化。几乎所有投资者都看好数据库上云趋势,就在云数据库、云原生数据库呼声高涨的同时,云数仓成为一个新的赛道,开始走入大众眼帘。只是,在分析什么是2025-11-05
最新评论